Blocking, not to be confused with the type that exposes one to the risk of physical injury, is a REALLY clever way to run experiments.
Blocking can be thought of as grouping experimental runs. And when experimental trials are grouped, interesting things can happen - not the least of which is you can really increase your signal to noise ratio.
Consider the following operational life data from Company ABC:
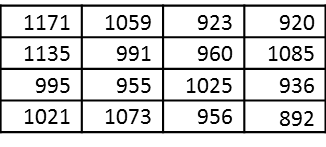 When the experiment is run in this fashion, we can calculate summary statistics, like the average, the median, the standard deviation, etc.
When the experiment is run in this fashion, we can calculate summary statistics, like the average, the median, the standard deviation, etc.
But, what if we actually knew what the product was for each of the data points. Now the data might look something like this:
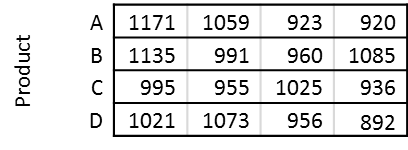 And now let’s say that we also knew the model for each of the data points. Now the data takes the form:
And now let’s say that we also knew the model for each of the data points. Now the data takes the form:
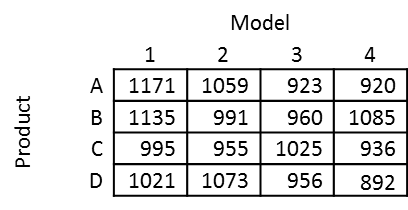 And finally let’s say we also know the manufacturing facility, now the data becomes:
And finally let’s say we also know the manufacturing facility, now the data becomes:
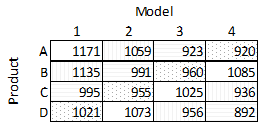 Each additional piece of information was a new block. Without blocks our data could be modeled as follows:
Each additional piece of information was a new block. Without blocks our data could be modeled as follows:
Operating Life = Average Operating Life + Noise
With blocking, the data can now be modeled as follows:
Operating Life = Average Operating Life + Product Offset + Model Offset + Facility Offset + Noise
where offsets, like the Product Offset are determined for each product by calculating the average operating life for each product and subtracting it from the overall average product life. So products that have an average operating life that is greater than the overall average operating life will have a positive offset, and those that have an operating life that is less than the overall average operating life will have a negative offset.
The bottom line?
With blocking, we gain a lot more information using the same number of experimental trials. Additionally, experiments can be blocked by time, which now gives you a way to account for shifts in the output over time, which is very helpful when experimenting in noisy on unstable environments.
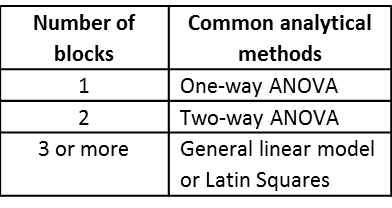
A few common approaches that use blocking are:
 Being a blockhead can be a good thing! It won’t improve your personality, but it will improve your experiments.
Being a blockhead can be a good thing! It won’t improve your personality, but it will improve your experiments.